
Don't Remove the Human From the Loop. Give Them a Better Role.
How test-driven machine learning made AutoML usable for people with zero data science background

Everyone’s talking about personal AI assistants right now, OpenClaw. And they’re genuinely useful. They write your emails, summarize your meetings, and plan your trips with a message from your phone.
But there’s a whole other side of AI that almost nobody talks about: using it to predict things. How many cups of coffee will you sell next week? Is it a good day to sell coffee? ☕️ Which customers are about to stop buying? Whether you should stock up on inventory or hold off. These are the kinds of decisions that business owners make on gut instinct every day, and AI can actually help with them.
The tools already exist. They’re called AutoML platforms. Basically, you plug in your business data, and the system builds a model that predicts sales, demand, churn, whatever matters to your business.
Not familiar? You’re not alone.
Researchers sat 16 regular people in front of one of these tools and tasked them to build a Machine Learning model. Not a single one could figure it out. These tools were built for data scientists, not the people who actually need them.
The irony is that building an ML model might feel foreign, but chances are you’re already using this exact technology every single day. You just don’t call it that.
When Spotify queues up a Discover Weekly playlist that somehow nails your mood. That’s a machine learning model trained on billions of listening patterns, predicting what you’ll want to hear next. When YouTube serves you an ad for running shoes, the week you started watching marathon training videos. That’s a prediction model matching your behavior to an advertiser’s audience. Even this post showing up in your feed right now? LinkedIn recently rebuilt its feed algorithm using large language models and transformer architectures, designed to understand what a post is actually about and match it to professional interests.
All of these are just Machine Learning (ML) models. Data goes in, patterns come out, and the system takes its best guess at what you’ll do next. The exciting part is that you can use the same tech to predict next week’s sales, spot customers who are about to churn, or figure out how many tomatoes to order for your sandwich shop using your own data to maximize your profit.
The tools to build your own ML models with machine learning already exist. Platforms like Azure ML, Google Vertex AI, and Amazon SageMaker all offer what the industry calls Automated Machine Learning. Think of it like this: if you want to forecast next month’s sales numbers or identify which customers are likely to stop using your service, these platforms let you do exactly that with your own data. The goal of these platforms is to let you avoid hiring a data scientist. Just upload your spreadsheet, press a button, and the system figures out the best ML model for you.
What actually happens is you upload your Excel file and immediately hit a wall. The system asks for your “target variable,” basically, what are you trying to predict? Maybe you are next week’s tomato sales. Then it wants to know if this is “regression” or “classification.” Translation: are you predicting a number (like sales), or a category (like yes/no)? Next up: pick an “evaluation metric.” RMSE, MAE, R²—just different ways of measuring how close the predictions are to reality. You came in hoping to finally get a handle on your produce orders, and now you’re staring at a form that looks like it was built for a stats professor.
What actually happens is you upload your Excel file and immediately hit a wall. The system starts asking questions that sound like they belong in a university lecture. What is your “target variable,” “regression or classification,” “evaluation metric?”
If you’ve ever opened one of these platforms, seen that wall of options, and quietly closed the tab. Trust me, you’re not alone. A research team at Williams College ran a study where they sat 16 non-technical folks in front of these AutoML tools. No one could tell the system what they actually wanted it to do. Zero for sixteen.
But what’s actually interesting is how the researchers tried to fix it.
The fix: make people do more, not less
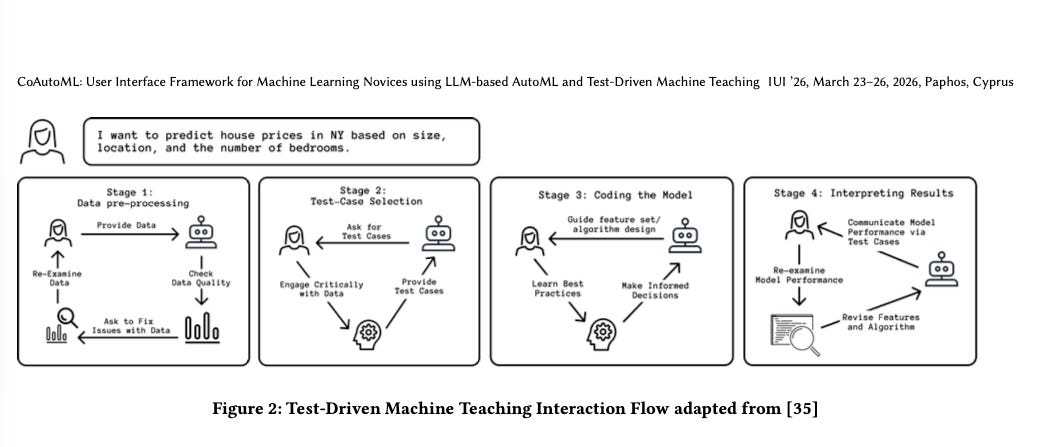
The researchers built a system called CoAutoML, and its most interesting feature is the counterintuitive way we design systems and giving shortcuts to users, i.e. Three-click rule. In CoAutoML, they actually gave more tasks to users.
Think of it like this: before CoAutoML builds anything, it asks you to write down a few real examples of what could happen. Imagine Spotify asking you to fill out a quick form before it builds your playlist.
Instead of the system getting that info directly from your history, the system gets your expertise upfront. Context in, recommendation out.
Does not make sense to manually do that for your Spotify, right? But for building an ML model, it works really well.
Test-Driven Machine Learning

This idea is concept Test-Driven Machine Learning. Test-Driven ML is the practice of defining test cases before model building. No one had actually built it into a working tool (to the best of my knowledge) until CoAutoML was built to take the concept in front of real users.

What happened when real people used it
The results were striking.
Participants started using tactile, embodied language to describe the experience. One said it felt like “being hands-on with the data… like touching the data.” Another said that the standard evaluation metrics meant nothing to them, but seeing their own expected output next to the model’s predicted output made everything clear. Seeing that they’d predicted 3.6 and the model predicted 3.58 gave them an intuitive grasp of model performance that no accuracy score ever could.
Even better, people started poking around. They’d try out extreme values just to see what happened. They’d spot patterns in their own data they’d never noticed before. Something they said they never would have caught if the system just did everything behind the scenes. If there were just a button that did it all, they never would have seen it.
The system didn’t teach these people machine learning. It gave them a way to express what they already knew, which was their domain expertise, in a format the machine could use.
By the end, participants reported high confidence in their ability to do ML tasks independently using the tool. Not because they suddenly understood gradient boosting, but because the interface matched the way they already thought about the problem: data goes in, a prediction comes out, and I can check whether it makes sense.
What this means if you’re building AI agents for data work
This is the part that matters if you’re thinking about agentic data teams, which, honestly, is what I spend most of my time on these days.
Most people in the AutoML and AI agent world assume the goal is total automation. Remove the human. Make it seamless. But this research points to something different: the best systems aren’t the ones that do everything for you. They’re the ones that ask you the right questions at the right time, in words you actually understand.
For SMEs without data teams, this distinction is critical. When you’re building AI agents that handle data pipelines, analysis, and reporting for a small company, you can’t assume the person on the other end knows what a “target variable” is. But you also can’t just hide everything behind a black box, because then they won’t trust the output or act on it.
The CoAutoML research points to a middle path: give people a role that matches how they already think. Don’t ask them to be data scientists. Let them say what they know in their own words, and let the system handle the translation into whatever the ML pipeline needs. Ask them to be domain experts, which they already are!
Starkova, V. & Howley, I. (2026). CoAutoML: User Interface Framework for Machine Learning Novices using LLM-based AutoML and Test-Driven Machine Teaching. IUI '26, Paphos, Cyprus. doi.org/10.1145/3742413.3789153