
Understanding Big-O Notation with Ruby
If the whole Big-O notation thing baffled you in college, guess what? You're in great company! 😅 Many of us had our share of head-scratching moments.

Big-O Notation in Ruby
In college, Big-O Notations was taught in one of our courses. I really could not connect the dots back then. Big-O notations felt too theoretical at that time.
So, as a professional developer, I relied upon performance tools like rack-mini-profiler, Benchmark, bullet, etc.
When 3rd party monitoring apps like AppSignal and New Relic started becoming good at monitoring performance, I began creating rules when writing code to avoid performance issues later when my code hits production.
These are some of my "performance" rules:
1. Be Mindful with Loops
Rule: Reduce database hits inside loops.
# Bad
User.all.each do |user|
user.update_attribute(:status, "active")
end
# Good
User.update_all(status: "active")2. Optimize Database Queries
Rule: Avoid N+1 queries by eager loading associated records.
# Bad
User.all.each do |user|
puts user.profile.name
end
# Good
User.includes(:profile).each do |user|
puts user.profile.name
endNote: Although, if you use the Russian Doll Caching strategy, this might not apply.
3. Background Jobs for Time-Consuming Tasks
Rule: If all else fails, move long-running tasks to background jobs. Pray that the user does not need the data ASAP 🙏
# Using Sidekiq or similar
LongTaskWorker.perform_async(user_id)I have realized you can get by with your app's performance by learning those simple rules.
However, having a solid foundation in your bag that has been used since 1894 might be a good idea.
What is Big-O notation?

In plain words, Big-O notation describes the performance of your code using algebraic terms. Performance in this context refers to either the speed of execution or the amount of RAM the code consumes.
In computer science, these concepts are more formally known as 'time complexity' for speed and 'space complexity' for RAM usage. Big-O notation is used for both, but we're going to focus on speed here to simplify our discussion.
Big-O in real-life
In a web application, handling a process that involves sorting or searching through 100 data entries will naturally be slower compared to dealing with just 10 entries.
The key question is: how much slower is it? Does the time taken increase 10x, a 100x, or perhaps even a 1000x?
This variance in processing speed might not be evident when dealing with smaller data sets.
However, the situation changes if your application's performance degrades significantly with the addition of each new entry in the database.
Such a decline in speed becomes a major concern, particularly as the volume of data grows larger in the app.
Understanding Big O notation is crucial in this context. It helps developers predict how their code will scale as data volumes increase, allowing them to choose the most efficient algorithms and data structures.
By anticipating performance issues before they occur, developers can optimize their applications for speed and efficiency, ensuring a smoother user experience even as data grows. This foresight is invaluable in maintaining a high-performing web application over time.
Here's a super accurate emoji-based representation of Big-O notations to give you an idea of how fast they are as your data scales:
🚀 O(1) - Speed does not depend on the scale of the dataset
🚄 O(log n) - If you have ten times more data, it only takes twice as long to process.
🚗 O(n) - If the amount of data increases tenfold, the processing time also increases tenfold.
🚲 O(n log n) - If you increase the data by ten times, the processing time will roughly increase by twenty times.
🏃♂️ O(n^2) - If the amount of data is multiplied by ten, the processing time increases by a factor of one hundred.
🚶♂️ O(2^n)- Doubling the amount of data leads to an exponential increase in processing time, making it significantly longer.
Big-O Notations In-depth
🚀 O(1)
O(1) indicates that the execution time of an operation remains constant, regardless of the size of the data set.
Example of accessing an element in a hash; the time taken is independent of the hash's size:
# Access time remains
# constant for these
hash_with_100_items[:a]
hash_with_1000_items[:a]
hash_with_10000_items[:a]As a result, hashes generally perform better than arrays for large datasets. Here's another Ruby example:
# Retrieving an item
# from arrays of varying
# sizes
array_with_100_items[50]
array_with_1000_items[50]
array_with_10000_items[50]In this case, fetching an element at a specific index (like the 50th position) takes the same amount of time, regardless of the array's size.
🚄 O(log n)
O(log n) describes an algorithm where the time it takes to complete a task increases logarithmically in relation to the size of the dataset.
This means that each time the dataset doubles in size, the number of steps required increases by a relatively small, fixed amount.
O(log n) operations are efficient and much faster than linear time operations for large datasets.
Here is a Ruby example illustrating O(log n) complexity:
Binary Search:
A binary search algorithm in a sorted array is a classic example of O(log n) complexity. At each step, it divides the dataset in half, significantly reducing the number of elements to search through.
Here’s an example of a Ruby code of binary search. We compare the time difference with benchmark when we double the dataset.
Code:
require 'benchmark'
def binary_search(array, key)
low = 0
high = array.length - 1
# This loop runs as long
# as the 'low' index is
# less than or equal to
# the 'high' index
while low <= high
# Find the middle
# index of the
# current range
mid = (low + high) / 2
value = array[mid]
# If the value is less
# than the key, narrow
# the search to the
# upper half of the
# array
if value < key
low = mid + 1
# If the value is
# greater than the
# key, narrow the
# search to the
# lower half of
# the array
elsif value > key
high = mid - 1
# If the key is found,
# return its index
else
return mid
end
end
# If the key is not
# found in the
# array, return nil
nil
end
# Example usage with an
# array of 100 million
# elements
array = (1..100000000).to_a
puts Benchmark.measure {
binary_search(array, 30)
}
# Example usage with an
# array of 200 million
# elements
array = (1..200000000).to_a
puts Benchmark.measure {
binary_search(array, 30)
}
# Example usage with an
# array of 300 million
# elements
array = (1..300000000).to_a
puts Benchmark.measure {
binary_search(array, 30)
}In this code, the binary search algorithm has a time complexity of O(log n) because it divides the search interval in half with each step.
In each iteration of the while loop, it either finds the element or halves the number of elements to check.
This halving process continues until the element is found or the interval is empty.
As a result, the time to complete the search increases logarithmically with the size of the array (n), making binary search efficient for large datasets.
Result:

🚗 O(n)
O(n) describes the time complexity of an algorithm where the time to complete a task grows linearly and in direct proportion to the size of the input data set. This means that if you double the number of elements in your data set, the algorithm will take twice as long to complete.
Here is a Ruby example illustrating O(n) complexity:
Summing all elements in an array:
In this example, the time to sum all elements increases linearly with the number of elements in the array.
Code:
require 'benchmark'
def sum_array(array)
sum = 0
# Iterating over each
# element in the array
array.each do |element|
# Adding each element
# to the sum
sum += element
end
# Returning the
# total sum
sum
end
# Summing an array of
# 100 million elements
array = (1..100000000).to_a
puts Benchmark.measure {
# The time taken here is
# proportional to the
# array's size
sum_array(array)
}
# Summing an array of
# 200 million elements
array = (1..200000000).to_a
puts Benchmark.measure {
# Time taken will be roughly
# twice that of the 100
# million array
sum_array(array)
}
# Summing an array of
# 300 million elements
array = (1..300000000).to_a
puts Benchmark.measure {
# Time taken will be roughly
# three times that of the
# 100 million array
sum_array(array)
}In this code, the sum_array function has an O(n) complexity because it involves a single loop that iterates over each element of the array exactly once.
The time taken to execute this function scales linearly with the number of elements in the array (n).
Therefore, if you double the size of the array, the time to sum the array also doubles, which is characteristic of linear time complexity.
Result:

🚲 O(n log n)
O(n log n) describes the time complexity of an algorithm where the time to complete a task increases at a rate proportional to the number of elements in the data set (n) multiplied by the logarithm of the number of elements (log n).
Here is a Ruby example illustrating O(n log n) complexity:
Merge Sort:
Merge Sort is a classic example of an algorithm with O(n log n) complexity. It divides the array into halves, sorts each half, and then merges them back together.
Code:
require 'benchmark'
def merge_sort(array)
# Base case: a single
# element is already
# sorted
if array.length <= 1
array
else
# Find the middle
# of the array
mid = array.length / 2
# Recursively sort
# the left half
left = merge_sort(array[0...mid])
# Recursively sort
# the right half
right = merge_sort(array[mid..-1])
# Merge the two
# sorted halves
merge(left, right)
end
end
def merge(left, right)
sorted = []
# Until one of the arrays
# is empty,pick the smaller
# element from the front
# of each array
until left.empty? || right.empty?
if left.first <= right.first
sorted << left.shift
else
sorted << right.shift
end
end
# Concatenate the remaining
# elements (one of the arrays
# may have elements left)
sorted.concat(left).concat(right)
end
# Benchmarking with
# 10 million elements
array = (1..10000000).to_a
puts Benchmark.measure {
merge_sort(array)
}
# Benchmarking with
# 20 million elements
array = (1..20000000).to_a
puts Benchmark.measure {
merge_sort(array)
}
# Benchmarking with
# 30 million elements
array = (1..30000000).to_a
puts Benchmark.measure {
merge_sort(array)
}
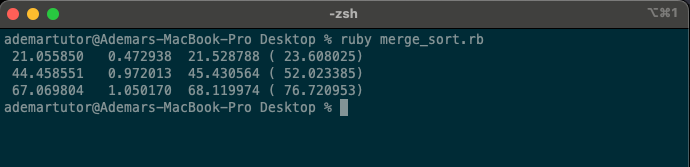
The merge_sort function exhibits O(n log n) complexity because it involves a divide-and-conquer approach.
The array is repeatedly divided into halves (resulting in a logarithmic number of divisions, i.e., log n), and each half is sorted and then merged.
The merging process for each level is linear in the size of the input (i.e., n), leading to a total time complexity of O(n log n).
This makes merge sort much more efficient for large datasets compared to algorithms with quadratic time complexities (like bubble sort or insertion sort), especially as the size of the data increases.
Result:
🏃♂️ O(n^2)
O(n^2) describes the time complexity of an algorithm where the time to complete a task is proportional to the square of the number of elements in the input dataset. This means that if the number of elements doubles, the time to complete the task increases by four times. Algorithms with O(n^2) complexity are generally less efficient for large datasets compared to O(n log n) or O(n) algorithms.
Here is a Ruby example illustrating O(n^2) complexity.
Bubble Sort:
Bubble Sort is a simple sorting algorithm that repeatedly steps through the list, compares adjacent elements, and swaps them if they are in the wrong order. The pass through the list is repeated until the list is sorted.
Code:
require 'benchmark'
def bubble_sort(array)
n = array.length
# Loop until no more swaps are needed
loop do
swapped = false
# Iterate through the array. The '-1' is because Ruby arrays are zero-indexed,
# and we're comparing each element with the next.
(n-1).times do |i|
# Compare adjacent elements
if array[i] > array[i+1]
# Swap if they are in the wrong order
array[i], array[i+1] = array[i+1], array[i]
# Indicate a swap occurred
swapped = true
end
end
# Break the loop if no swaps occurred in the last pass
break unless swapped
end
# Return the sorted array
array
end
# Benchmarking with 10,000 elements
array = (1..10000).to_a.shuffle
puts Benchmark.measure {
bubble_sort(array)
}
# Benchmarking with 20,000 elements
array = (1..20000).to_a.shuffle
puts Benchmark.measure {
bubble_sort(array)
}
# Benchmarking with 30,000 elements
array = (1..30000).to_a.shuffle
puts Benchmark.measure {
bubble_sort(array)
}
In this bubble_sort method, the O(n^2) complexity arises from the nested loop structure:
a) The loop construct potentially iterates n times (in the worst case where the array is in reverse order).
b) Inside this loop, there's a (n-1).times loop that also iterates up to n-1 times for each outer loop iteration.
This nesting of loops, where each loop can run 'n' times, leads to the time complexity of O(n^2).
Result:

🚶♂️ O(2^n)
O(2^n) describes the time complexity of an algorithm where the time to complete a task doubles with each additional element in the input data set. This kind of complexity is typical in algorithms that involve recursive solutions to problems where the solution involves creating two or more subproblems for each problem. Such algorithms are often seen as inefficient for large datasets due to their exponential time growth.
Here is a Ruby example illustrating O(2^n) complexity.
Fibonacci Sequence (Recursive Implementation):
A classic example of O(2^n) complexity is the recursive calculation of the Fibonacci sequence, where each number is the sum of the two preceding ones.
Code:
require 'benchmark'
def fibonacci(n)
return n if n <= 1
fibonacci(n - 1) + fibonacci(n - 2)
end
puts Benchmark.measure {
fibonacci(10)
}
puts Benchmark.measure {
fibonacci(20)
}
puts Benchmark.measure {
fibonacci(30)
}The number of operations grows exponentially with the input size, characteristic of O(2^n) time complexity. This exponential growth makes these algorithms impractical for large input sizes due to the rapid increase in computation time.
Result:

Summary
You should not be using these code examples in production apps. There are built-in Ruby sort and search. And if you are sorting records (in PostgreSQL), please use the database feature.
I hope you can appreciate Big-O notation and apply this to your daily work. 🚀
Hello there!
Do you have a startup idea or an exciting project you’re passionate about? I’d love to bring your vision to life!
I’m a software developer with 13 years of experience in building apps for startups, I specialize in Rails + Hotwire/React.
Whether you’re looking to innovate, grow your business, or bring a creative idea to the forefront, I’m here to provide tailored solutions that meet your unique needs.
Let’s collaborate to make something amazing!
Sincerely,
Ademar Tutor
hey@ademartutor.com