
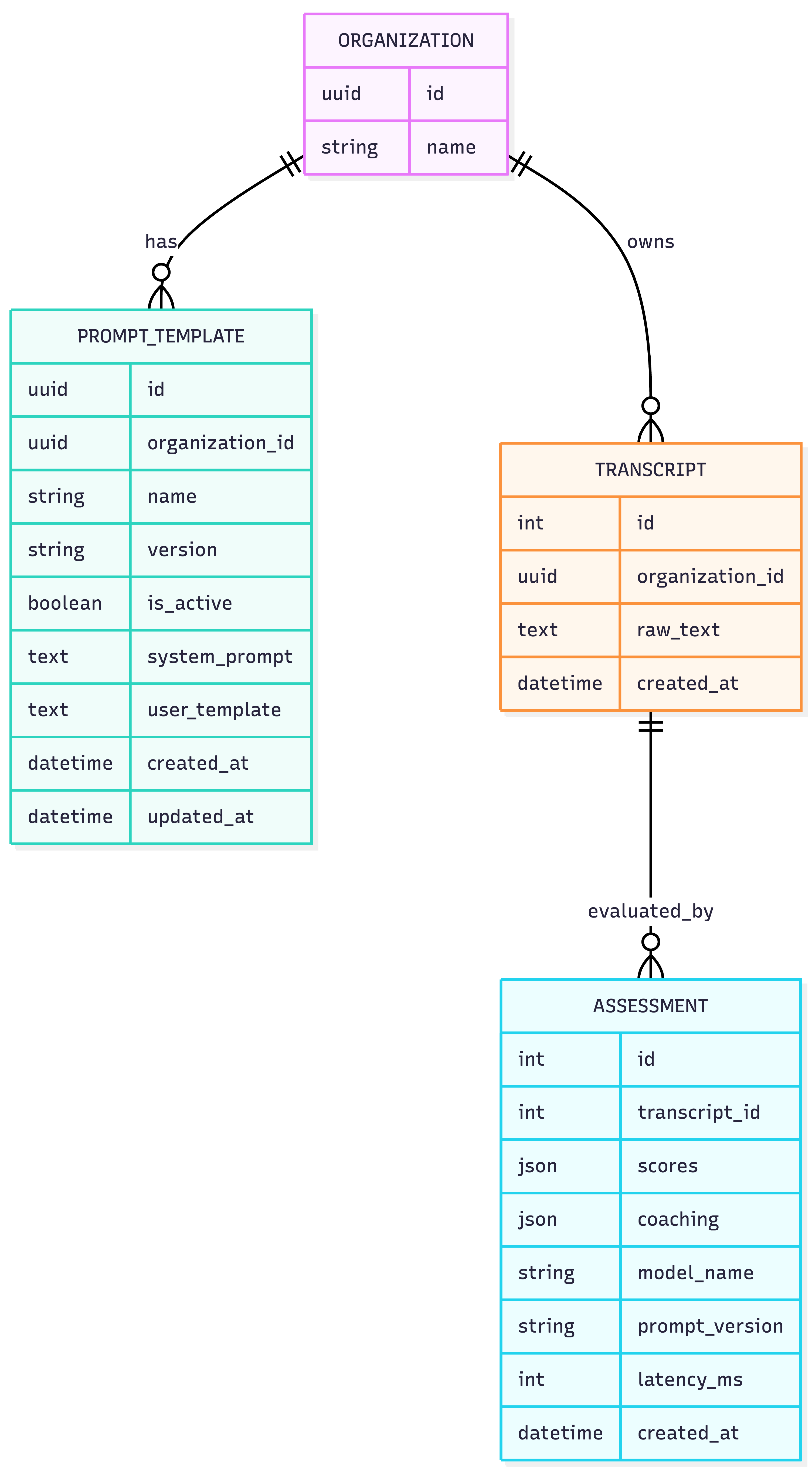
Prompt templates evaluation contracts
Versioned rubrics in the database

Who this is for:
Engineers building LLM-as-a-Judge or LLM evaluation pipelines
MLOps/Platform teams who need audit trails for AI outputs
Tech leads evaluating how to manage prompt configuration at scale
What you’ll get:
A concrete database pattern (Postgres + SQLAlchemy) for versioned prompt templates
API design for tenant-scoped prompt activation
An audit trail that links every assessment to its prompt version
I previously thought that “LLM apps are just prompts + glue.” Basically, they are just “LLM Wrappers.”
After building a few LLM apps, I disagree. The prompt isn’t copywriting. It’s a production configuration.
If your prompt changes, your system behavior changes. If your system behavior changes, your evaluation metrics shift. And if your evaluation shifts without an audit trail, you end up “improving” the product by accident because you changed the yardstick, not the thing being measured.
What happens when there is no prompt versioning?
Teams burn entire sprints chasing phantom regressions. Scores drop 15% after a “minor tweak.” Was the tweak the model, the data, or the prompt? Nobody knows, because nobody recorded which prompt produced which assessment.
Research on LLM-as-a-Judge systems shows that even small prompt variations can significantly affect scores, rankings, and bias characteristics, introducing what researchers call “evaluation instability driven by prompt mis-specification rather than model capability.”
A 2024 EMNLP study found that LLM performance is highly sensitive to the prompts utilized, and this variability poses challenges for accurate assessment.
Meanwhile, scoring bias and prompt sensitivity studies show that even state-of-the-art judges can have large per-instance score variance under simple prompt perturbations like rubric order or score anchoring.
If you’re using LLM-as-a-Judge in production, you’re one undocumented prompt edit away from:
Unexplainable metric shifts that erode stakeholder trust
Compliance gaps when auditors ask for evaluation lineage
Wasted debugging cycles because you can’t isolate variables
False confidence in “improvements” that were just measurement drift
That’s why modern teams treat prompts as versioned contracts and store them like contracts: in a database and recorded on every evaluation artifact. This fits the broader shift toward product-level evaluation (not “model vibes”) that’s showing up in 2025 eval playbooks.
Is this post for you?
Ask yourself:
Have you ever shipped a prompt change and couldn’t explain why scores shifted?
Do you store prompts in code but have no record of which version produced which output?
Are different customers (or tenants) asking for different evaluation criteria and you’re copy-pasting prompts to handle it?
Could you answer, right now, “which prompt version generated this assessment 3 months ago?”
If any of these hit home, keep reading. This post breaks down a concrete pattern from the app I’ve built llm-as-a-judge-sales-coach (multi-tenant “LLM as an evaluator” app for sales coaching.):
Prompt templates as evaluation contracts: versioned rubrics stored in Postgres, with an “active template per org” and an assessment audit trail that records prompt version.
Why is “prompt templates as contracts” trending?
LLM evaluation is prompt-sensitive. A small rubric tweak can swing agreement metrics or produce systematically different “judgments.” Surveys and platform docs now call out prompt templates as a key driver of bias/variance in LLM-as-judge evaluation, which is why teams increasingly treat evaluation prompts as managed artifacts.
The goal is:
Version the prompt like a contract (v0, v1, …)
Activate exactly one contract per tenant
Record which contract produced each assessment
Evaluate changes offline before promoting them
That’s what this implementation does.
The pattern: prompt templates as a first-class database model
In the app, a prompt template is a row in prompt_templates:
organization_id (tenant boundary)
name
version (e.g., v0, v1, custom_v2)
system_prompt
user_template (must contain {transcript})
is_active (only one active per org)
The model is explicit about the “one active per org” invariant:
class PromptTemplate(Base):
"""
Only one template per organization can be active at a time.
"""
version = Column(String(20), nullable=False, default=”v0”)
is_active = Column(Boolean, default=False, server_default=”false”, nullable=False)Full Source: backend/app/models/prompt_template.py
Contract enforcement: “active template per org”
This is where the pattern truly shines.
When you create or update a template with is_active=True, the CRUD layer deactivates all other templates for that org:
def _deactivate_org_templates(db, organization_id):
db.query(PromptTemplate).filter(
PromptTemplate.organization_id == organization_id,
PromptTemplate.is_active == True,
).update({”is_active”: False})
def create(..., is_active=False):
if is_active:
_deactivate_org_templates(db, organization_id)
...Full Source: backend/app/crud/prompt_template.py
That gives you a clean tenant-safe guarantee:
each org can iterate on prompts independently
the runtime scorer always has a single “source of truth”
rollbacks become easy: just re-activate the prior version
The API exposes this in a very “config management” way:
GET /prompt-templates/active → fetch the active contract
POST /prompt-templates/{template_id}/activate → promote a version
@router.get(”/active”)
def get_active_template(...):
template = template_crud.get_active_for_org(db, org_id)
...
@router.post(”/{template_id}/activate”)
def activate_template(...):
updated = template_crud.update(db, template, is_active=True)Full source: backend/app/routers/prompt_templates.py
The default contract: hardcoded v0, persisted at org creation
You still want a sane default so the system works on day one.
This repo keeps the initial prompt as code constants:
SYSTEM (role + strict rules)
USER_TEMPLATE (JSON schema + {transcript} insertion)
def create_default_for_org(db, organization_id):
from app.prompts.prompt_templates import SYSTEM, USER_TEMPLATE
return create(..., version=”v0”, system_prompt=SYSTEM, user_template=USER_TEMPLATE, is_active=True)Full source: backend/app/crud/prompt_template.py
And the user template makes the “contract” concrete by embedding a strict JSON schema and requiring the transcript placeholder:
CONVERSATION TRANSCRIPT:
{transcript}
Provide your assessment as valid JSON matching the schema above.Full source: backend/app/prompts/prompt_templates.py
Auditability: template version recorded with each assessment
This is the “evaluation contract” payoff.
The scoring pipeline returns (assessment_data, model_name, prompt_version):
template = get_active_template(...)
system, user = build_prompt(..., system_prompt=template.system_prompt, user_template=template.user_template)
prompt_version = template.version
...
return assessment_data, model_name, prompt_versionFull source: backend/app/services/scorer.py
Then the /assess router persists that prompt version on the Assessment record:
data, model_name, prompt_ver = score_transcript(...)
assessment = Assessment(
transcript_id=transcript.id,
scores=data[”scores”],
coaching=data[”coaching”],
model_name=model_name,
prompt_version=prompt_ver,
)Full source: backend/app/routers/assess.py
And the Assessment model explicitly indexes it for querying later:
prompt_version = Column(String, nullable=False, index=True)Full source: backend/app/models/assessment.py
So months later you can answer:
“Which prompt version produced this coaching output?”
“Did v3 increase scores artificially vs v2?”
“When we changed the rubric, what shifted?”
This is what it means to treat prompts like contracts: you can’t audit what you didn’t record.
How this enables “safe prompt iteration” without drift chaos
Once your prompt is a contract, you can run a clean workflow:
Draft v3 — You tweak the rubric to catch a new failure mode. No stress, it’s not live yet.
Preview it — Hit the preview endpoint. See exactly what output the new prompt produces. No guessing.
Evaluate offline — Run it against your gold set. Compare v3 vs v2 side-by-side. Did scores improve, or did you just move the goalposts?
Promote it — One API call. The new contract is live. The old one is still in the database if you need to roll back.
Observe with confidence — Every assessment is stamped. When your PM asks “what changed?” You know. When a customer disputes a score, you can show them exactly which rubric produced it.
This is the difference between “I think we improved the model” and “I can prove v3 outperforms v2 on our gold set, and here’s the audit trail.”
What does this actually save you?
For a team running 1,000+ evaluations/month, this pattern will pay for itself the first time the team needs to answer “why did tenant X’s scores change?”. A question that will take half a day and now takes one SQL query.
The takeaway
If you’re using LLM-as-a-Judge, your prompt isn’t “just a prompt.”
It’s the scoring contract. It defines what “good” means.
So treat it like production configuration:
store it in the DB
version it
activate it per tenant
stamp every assessment with its version (and eventually its ID)
evaluate changes before you ship them
That’s how you keep evaluation from drifting and keep your improvements real.