
AI agents work better when you give them less freedom
A neuroscience paper showed me how to build better AI data teams for businesses.

You’ve probably had this experience: you ask ChatGPT to write a report based on some spreadsheets you pulled from the finance department. It gives you something that looks right, but when you actually read the details, it gives you a beautiful answer to a question you didn’t ask. It makes up column names.
Now imagine that happening inside an automated data pipeline run by AI agents. At 2am. With no one watching.
This is the main issue in building AI agents that actually do useful work for companies. The same flexibility that makes LLMs impressive is exactly what makes them dangerous when you need reliability.
A research group at EPFL built a system called AmadeusGPT in 2023. It analyzes animal behavior in neuroscience labs using natural language. On the surface, it has nothing to do with business. But it shows something important: AI agents become more reliable when you give them less autonomy, not more.
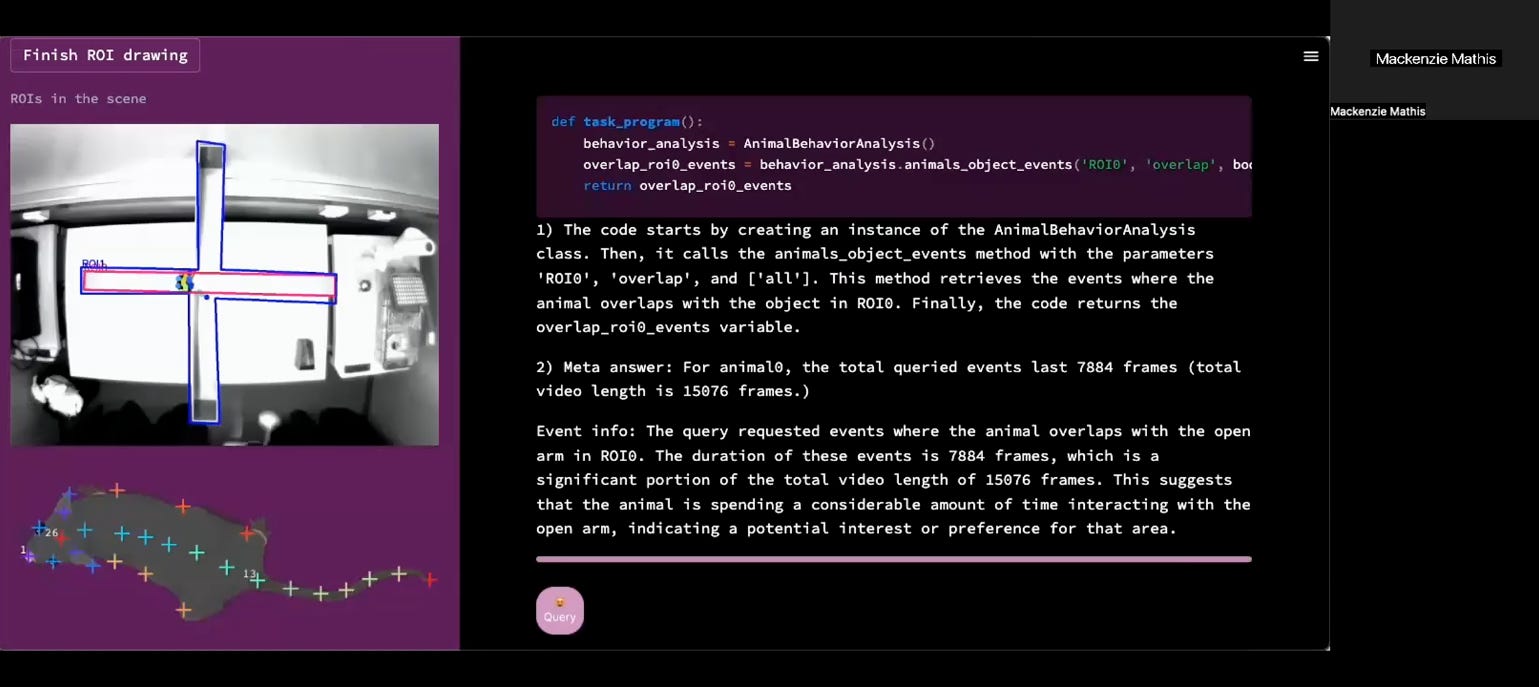
What the researchers actually built
The EPFL team faced a problem that should sound familiar. Labs generate piles of video data, such as mice running through mazes or horses on treadmills. Analyzing that data means stitching together pretrained models like DeepLabCut for animal trs Segment Anything for object segmentation, etc. These are’ etc. These are work that traditionally requires coding scripts, training models, or integrating multiple codebases. The problem is that people who understand biology often can’t code, and the people who can code often don’t understand the biology.
Sound familiar? Swap “biology” for “your business domain” and “video data” for “your sales pipeline,” and you’ve got the exact problem most SMEs face with their data.
Their solution was to put GPT-3.5 in charge of writing and executing the analysis code based on plain language questions from researchers. A scientist could type “When is the mouse on the treadmill?” and the system would determine which models to run, generate the Python code, execute it, and return the answer.
But here’s the part that matters: they didn’t just point ChatGPT at the problem and hope for the best. They built a system of constraints and supporting components around it. And those constraints are what made it work.
The orchestration lesson
The researchers identified four reasons why a raw LLM can’t reliably do this kind of work: (1) it doesn’t know your private tools and APIs, (2) it hallucinates functions when given too much implementation detail, (3) it runs out of context window on complex tasks.
Now, to be fair: context windows have grown 30x since this paper. GPT-3.5 had a 4,096 token limit; today we’re talking 128K–200K+. That specific constraint is fading. But the other three problems haven’t gone anywhere. The (2) model still hallucinates functions, (1) still doesn’t know your private tools. And ironically, (3) bigger context windows introduce their own issues. Models get distracted by irrelevant context, and costs scale with the number of tokens. The architectural lesson isn’t about token limits. It’s about how constraint and orchestration outperformed raw capability. That finding becomes even more relevant as models become more powerful.
Their fix was architectural, not just a better prompt. And the single most important design decision was this: they hid the implementation and only showed the interface.
Instead of feeding GPT the full source code of their analysis tools (hundreds of lines of Python per function) they gave it only the function documentation. What each function does, what it accepts, what it returns. Nothing else. It’s like giving a new employee a clear job description instead of dumping the entire company codebase on their desk.
The architecture
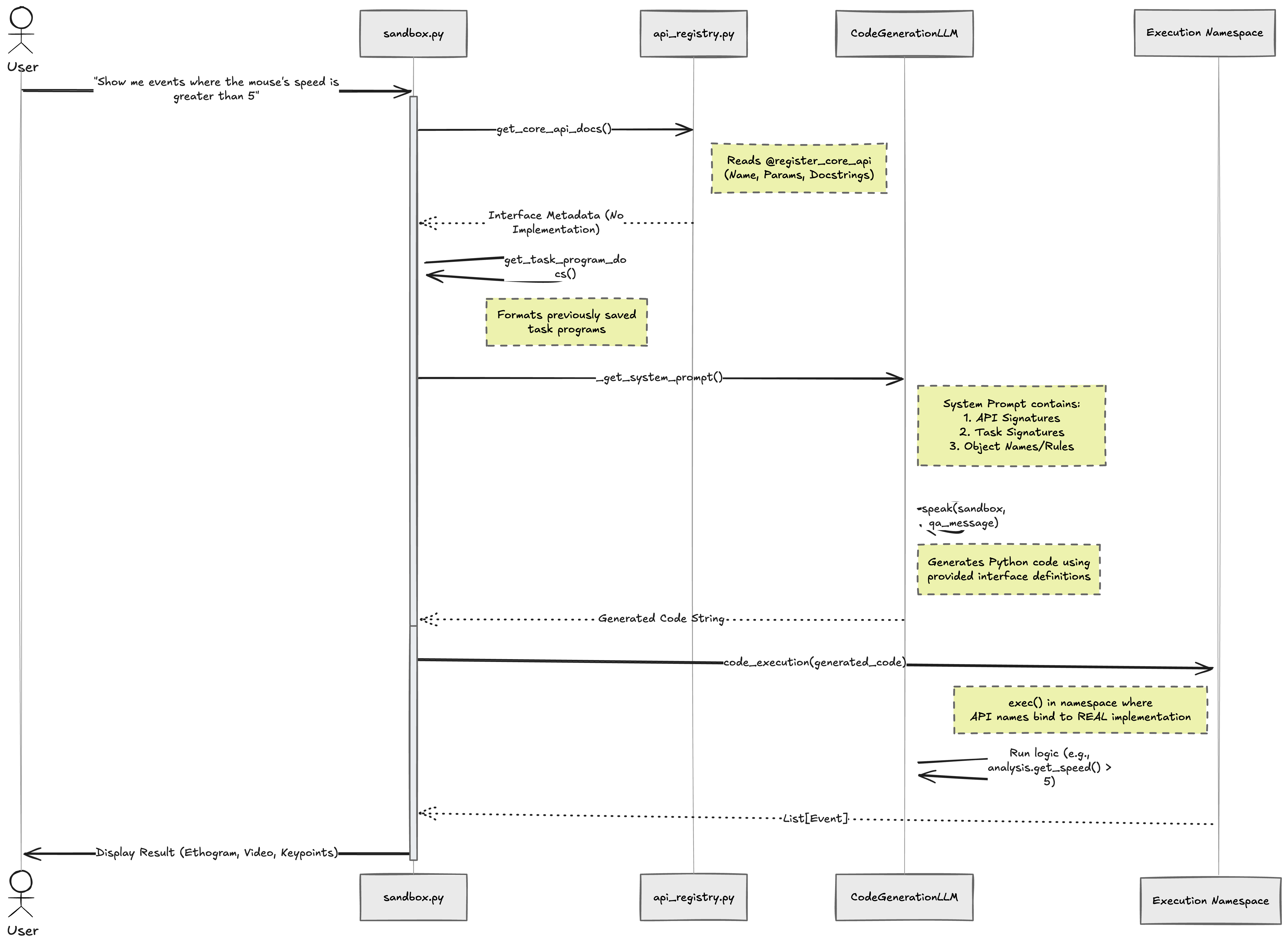
Here’s how they did it.
Step 1: Register only the interface, never the implementation.
A Python decorator (@register_core_api) captures only three things about each function: its name, its parameter types, and its docstring. The actual logic is discarded at the point of registration.
python
CORE_API_REGISTRY[func.__name__] = {
“name”: func.__name__,
“parameters”: inputs, # type annotations only
“description”: func.__doc__, # docstring only
}Step 2: Format those registrations as documentation for GPT.
A separate function (get_core_api_docs()) converts the registry into a clean, readable spec block. They are just function signatures and descriptions. No source code. Just the “job description.”
Step 3: Inject that documentation into the system prompt.
The code generator prompt explicitly tells GPT: “This block contains information about the core APIs... They do not contain implementation details but you can use them to write code.”
Step 4: GPT generates code using only the interface.
GPT sees signatures like get_animals_animals_events(cross_animal_query_list, bodypart_names, ...) with their docstrings, and writes code that calls these functions — without ever seeing the implementation behind each one. The real work happens in manager classes (animal_manager.py, object_manager.py, etc.) that GPT never touches.
The result:
GPT stopped inventing functions that didn’t exist. Token usage dropped because less context was needed. The system produced correct, executable code from plain English questions.
On a standardised animal behavior benchmark (MABe 2022 Behavior Challenge), this constrained system matched or outperformed dedicated machine learning models that had been specifically trained for the task. And with GPT-4 instead of GPT-3.5, the error rate on real user queries dropped from 18% to 10%.
What this means if you’re building (or buying) AI for your data
Here’s where this connects to what I think about every day:
building agentic data teams for SMEs.
Most of the AI hype you hear is about making models bigger, more capable, more autonomous. The promise is: just give the AI more freedom, and it’ll figure it out. But this paper demonstrates the opposite. The magic was in the constraints.

This maps directly to what I’ve learned from years of running engineering teams. The bottleneck in delivery is never talent. It’s orchestration. The handoffs, the QA loops, the “who checks if this works with our X number of existing features” problem. When you get the coordination right, a small team outperforms a big one. That’s true whether the team is human or artificial.
The takeaway
AmadeusGPT offers a crucial lesson for any business bringing AI into its data operations:
Design the interfaces your AI agents work through as carefully as you would design a job description for a new hire.
Define what each function does, what it accepts, and what it returns. Hide the rest. The narrower the surface area, the fewer ways the agent can be wrong.
And that principle extends beyond APIs. The researchers didn’t build one super-agent that did everything. They built a system of components with specific roles. A code generator agent, a rephraser agent, a self-correction agent, and an explainer agent. Each one had a narrow job and a clean interface to the others. Your agentic team should work the same way: one agent writes the query, another validates it, another explains the results.
They also planned for failure. The self-correction mechanism in AmadeusGPT didn’t prevent all errors, but it caught a significant number of them without human intervention. Good orchestration is not assuming that the first attempt will be perfect. It means building in checkpoints, retries, and graceful failure.
The Bottom line
The companies that will get the most value from AI in the next few years won’t be the ones using the most powerful models. They’ll be the ones who orchestrate AI agents most effectively with the right constraints, the right memory, and the right coordination among agents.
Paper: Ye, S., Lauer, J., Zhou, M., Mathis, A., & Mathis, M.W. (2023). AmadeusGPT: a natural language interface for interactive animal behavioral analysis. NeurIPS 2023.
Hello, I’m Ademar Tutor. I’m researching how to agentic data teams for SMEs. An AI system that delivers the data capabilities of a full data team, without the headcount. I’m currently completing my Master’s in AI at the University of Waikato. I share what I’m learning along the way! Follow me on LinkedIn if that’s a problem you’re thinking about too.